

微信社群管理助手,微信社群去重,邀请统计,社群管理机器人基于微信电脑客户端开发的群管辅助软件,为团队及企业提供智能营销及客户管理服务。会员说明1、不限群,不限微信号,同一台设备无限多开。2、另外,也有企微版必销客,企销客可以...
网站首页 > 网页数据抓取
-
发布了文章 2024-03-03
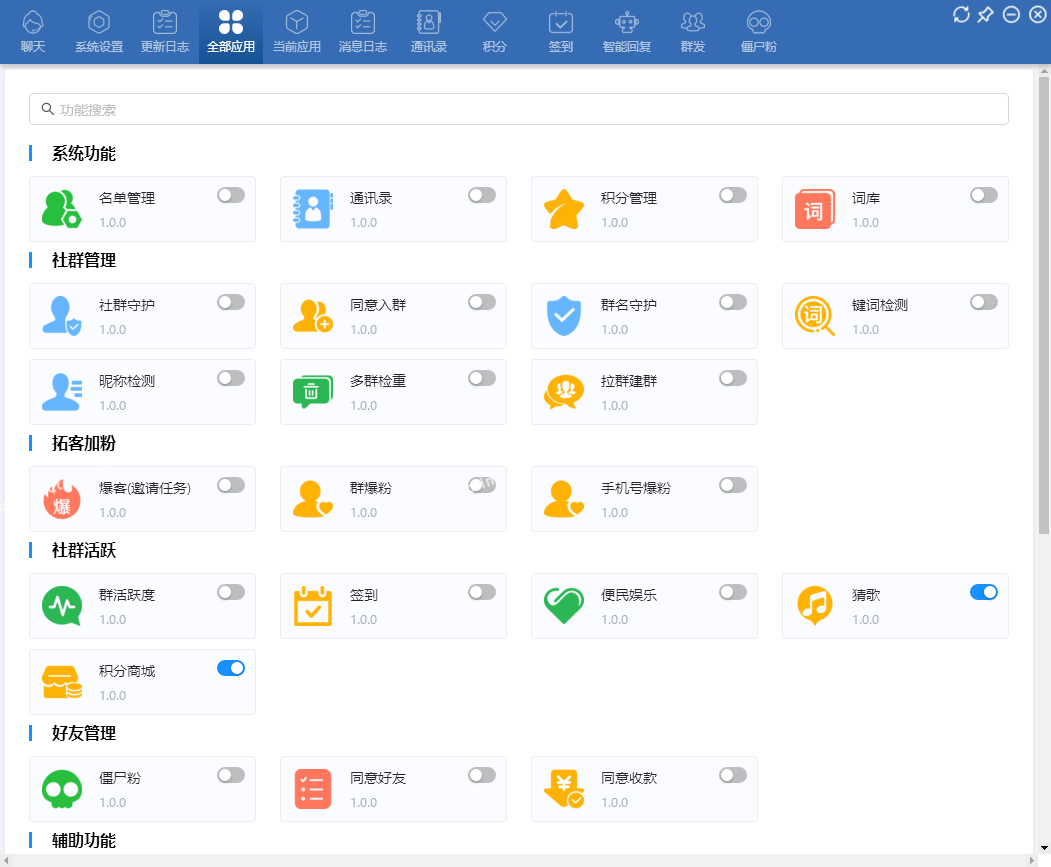
置顶微信社群管理助手,微信社群去重,含社群引流、社群运营、社群裂变、积分营销、群发转发、自动回复、清理僵尸粉等等智能功能
-
发布了文章 2023-12-12
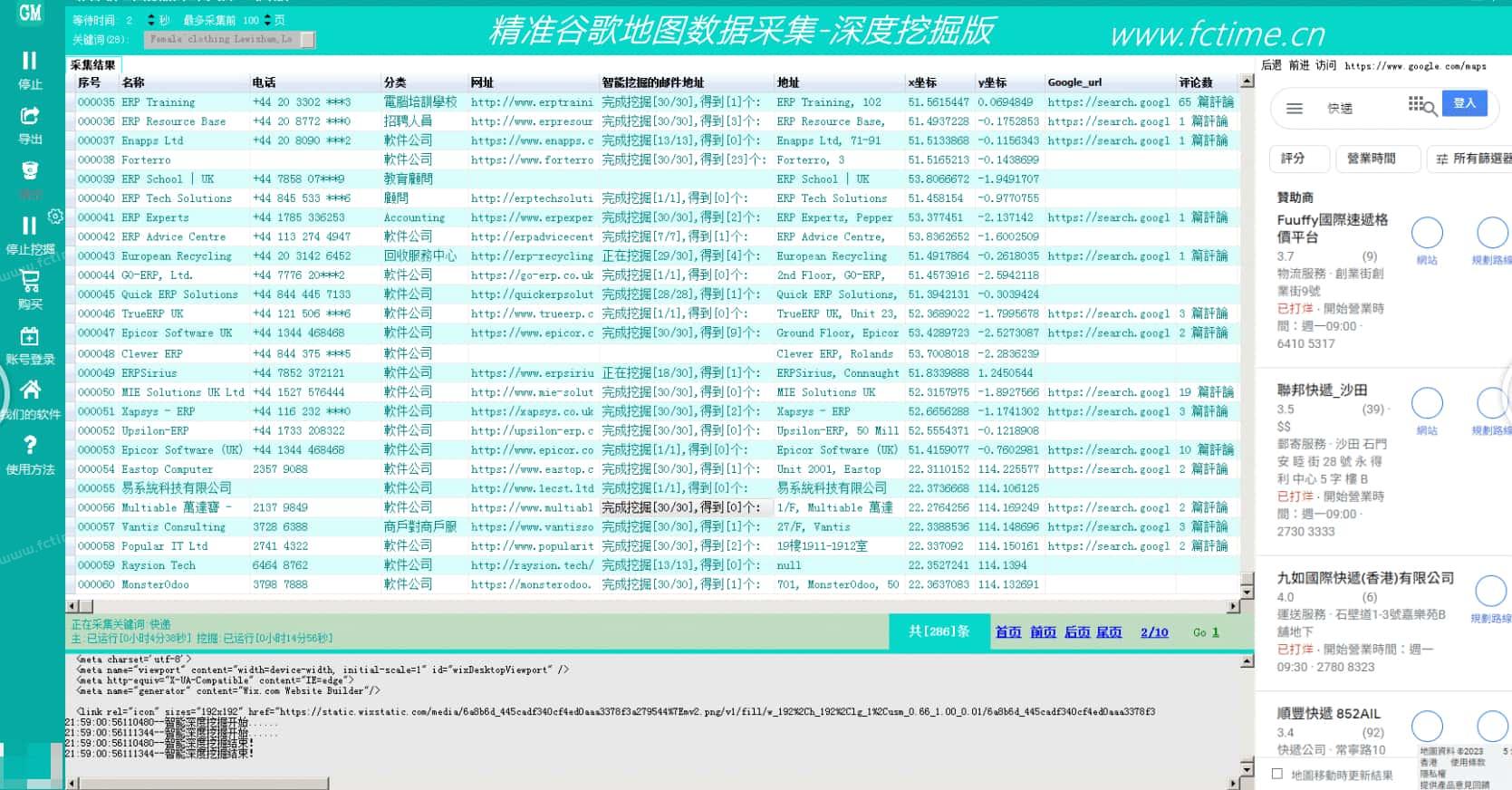
置顶精准谷歌地图外贸数据采集-深度挖掘(电脑版)
精准谷歌地图外贸数据采集-深度挖掘(电脑版)专为做外贸的朋友开发的一款基于谷歌地图数据采集的软件,可以采集任意国家、任意地区的公司地址、电话号码、邮件地址等数据。可以批量输入关键词采集、一键采集邮箱、一键导出、数据去重等,更...
-
发布了文章 2023-02-21
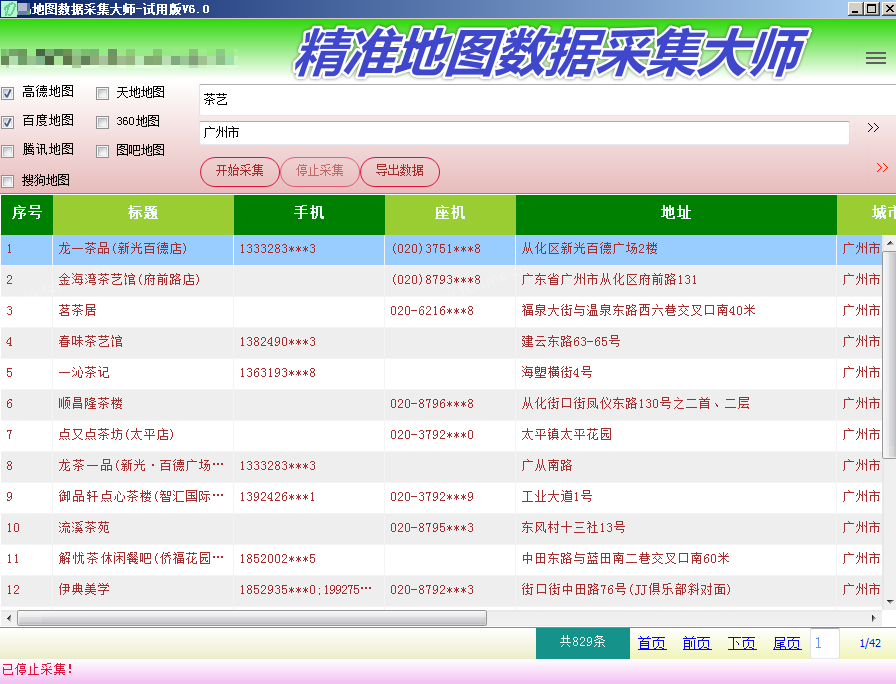
置顶精准地图数据采集大师详细介绍(电脑版,手机版)
精准地图数据采集大师详细介绍(电脑版,手机版)精准地图数据采集大师简介 精准地图数据采集大师安卓手机版是一款专业采集百度地图、360地图、高德地图、搜狗地图、腾讯地图、图吧...
-
发布了文章 2023-12-12
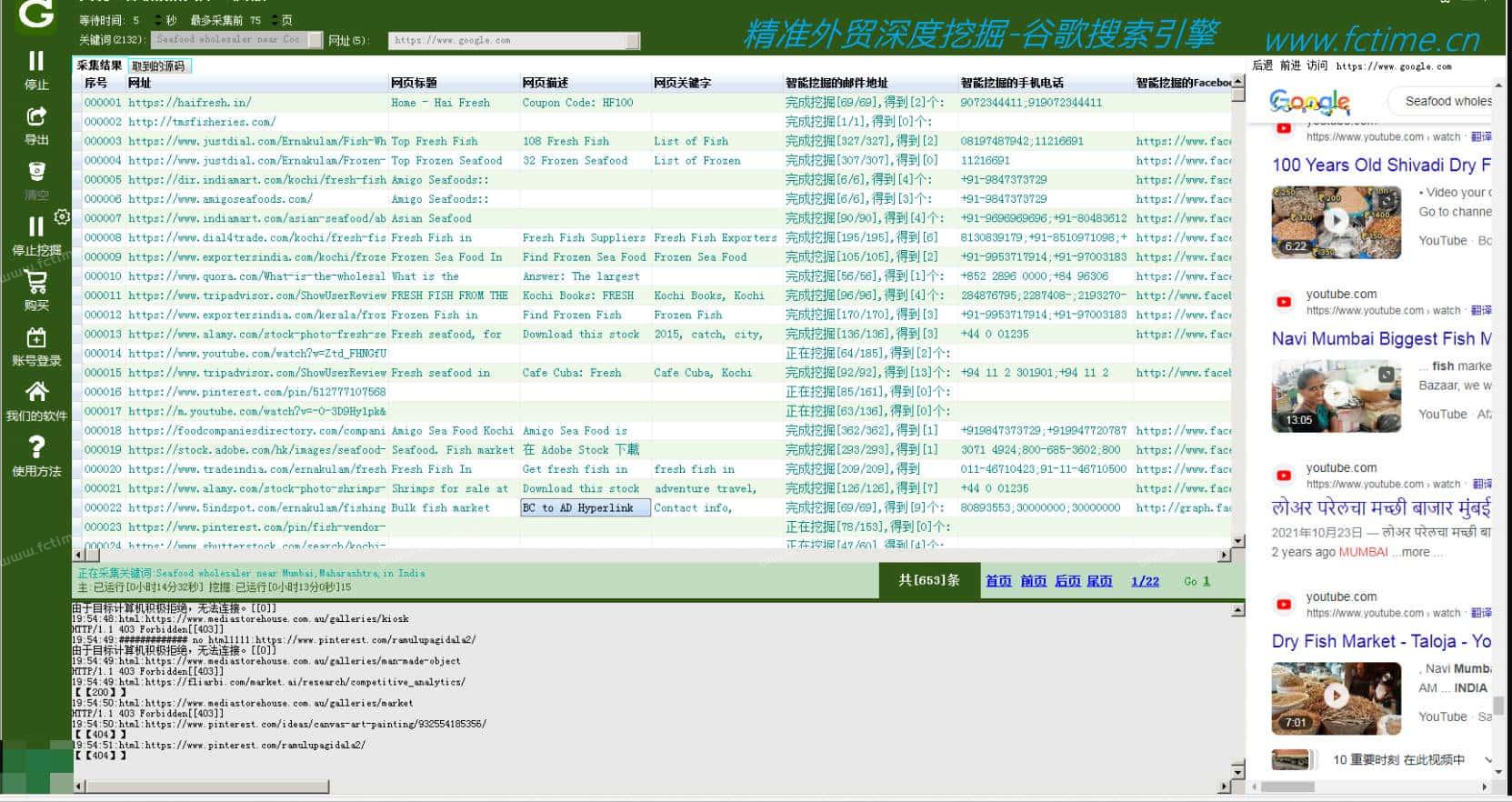
置顶精准谷歌搜索大师-外贸数据挖掘营销(电脑版)
外贸谷歌数据挖掘-精准谷歌搜索大师(电脑版)软件介绍谷歌搜索大师是一款以google搜索引擎作为基础进行智能数据挖掘的软件,采集的数据包括网站、标题、描述、邮件地址、手机或电话号码、facebook、linkin、twitt...
-
发布了文章 2025-03-20
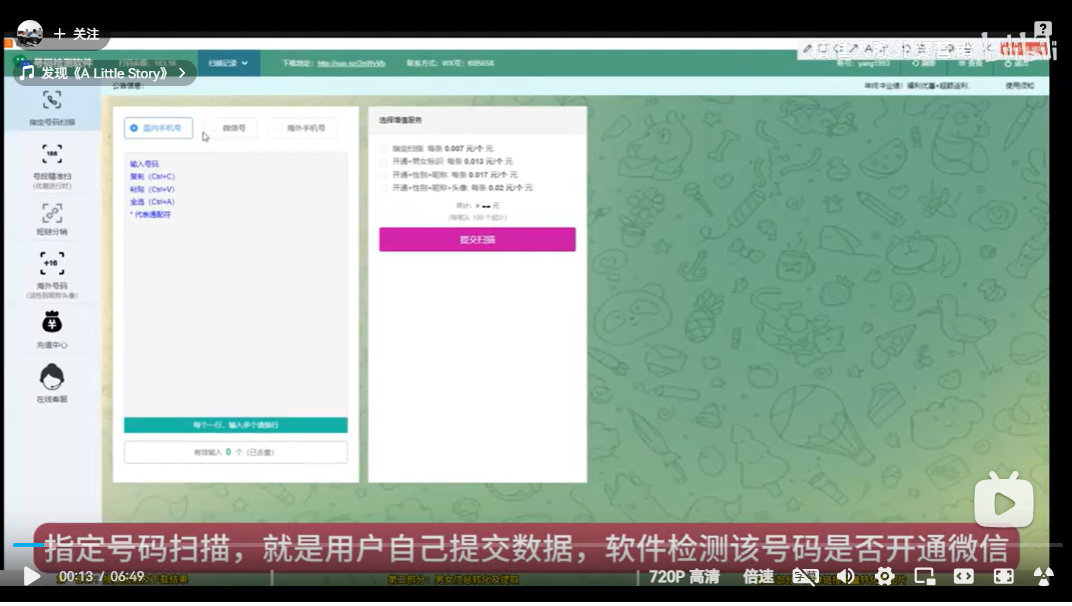
置顶 微信注册开通检测全功能版,可批量检测手机号码是否开通微信,国内号码筛选,港澳台号码筛选,国外号码,微信号QQ号等多种号码格式
微信检测可批量检测手机号码是否开通微信,国内号码,港澳台号码,国外号码,微信号QQ号等多种号码格式用户批量上传手机号码,平台将快速、自动、批量将手机号中有绑定或者开通微信的号码筛选出来,高速筛选、精准无痕,有效降低运营成本节...
-
发布了文章 2025-06-14
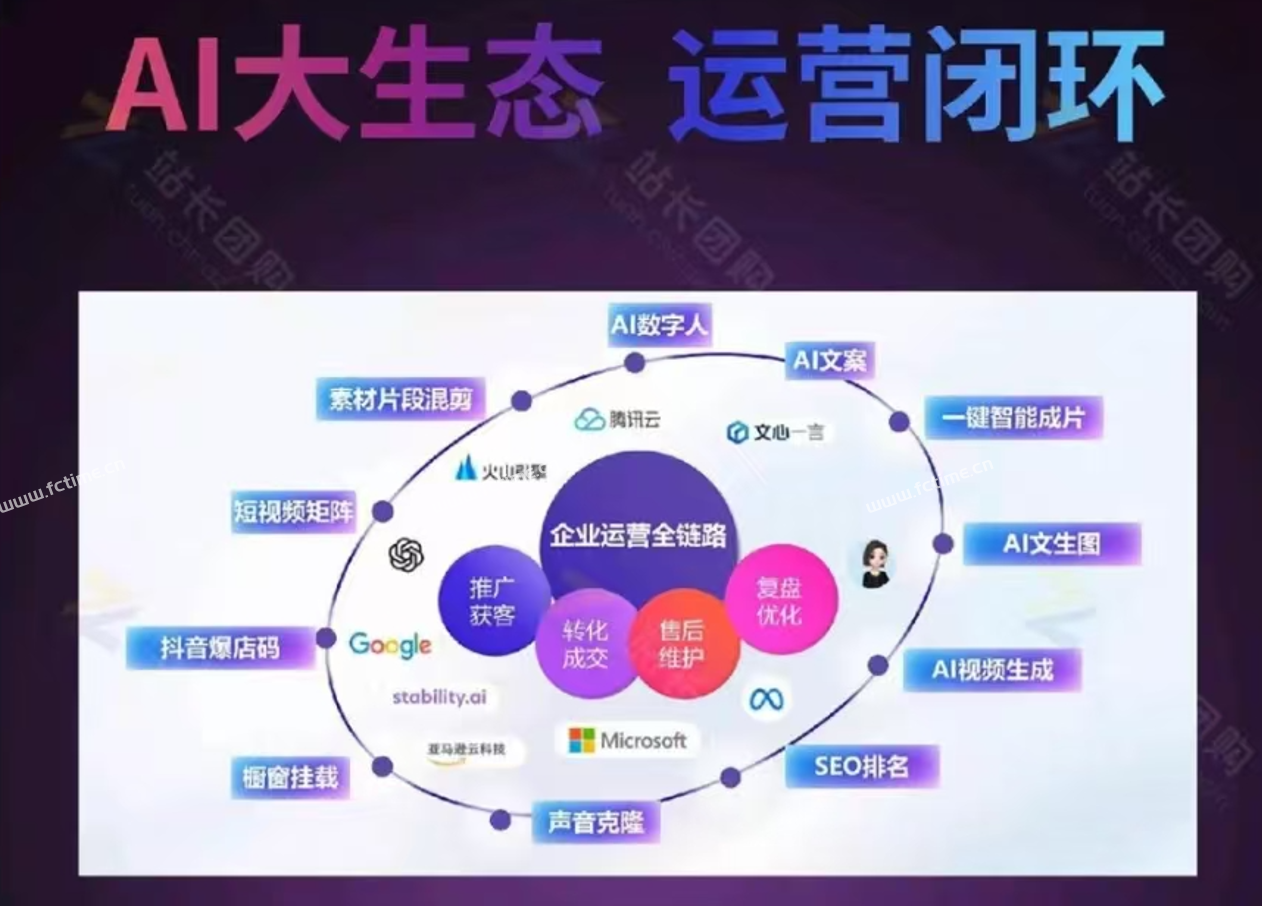
置顶企业短视频矩阵运营助手详细图文介绍,AI数字人,AI文案,AI视频
企业短视频矩阵运营助手详细图文介绍算力消耗:以积分形式消耗系统成本折算成积分,1元100积分以数字人克隆为例短视频矩阵整体功能截图手机版截图电脑端后台截图数据大屏矩阵授权短视频矩阵,任务管理图文矩阵管理UGC裂变码多模式视频...
-
做好的网站怎么才能被收录?
1.提交给各大搜索引擎2.站在用户的角度思考网页数据抓取,为满足用户需求撰写更新内容3.写好全站、栏目、文章网页数据抓取,每一个页面的标题、描述、关键词4.做好站内链接、tag、菜单、sitemap、图片alt、说明、替代文...
-

如何简单批量采集网页表格数据?
在日常工作中我们难免要从互联网上采集一些数据网页数据抓取,对于数据采集一般有两种方案:有编程基础的有编程能力的可以自己写个程序采集数据,原理主要就是:获取网页内容 + 匹配指定特征符内的文本 + 提取数据 + 数据入库或展示...
-

网站上的历史数据可以通过爬虫获取吗?
首先了解下网络爬虫的基本工作流程:1.先选取一部分精心挑选的种子URL;2.将这些URL放入待抓取URL队列;3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已...
-

不学网络爬虫,用Excel抓取数据,可以吗?
当然是可以的网页数据抓取,但是使用起来不是很灵活,没有python等语言抓取数据好处理,下面我大概介绍一下excel抓取数据的过程,实验环境win7+office2013,主要内容如下:1.新建一个excel文件网页数据抓取...
-
怎么免费从网上获取需要的数据?
我更常用的从网上获取数据的方法有两种,一是下载公开数据,可以从政府、企业、统计局等机构去下载公开数据网页数据抓取。二是通过Python编写网页爬虫,收集互联网的数据。比如我就抓取过:知乎粉丝过万所有用户,咪蒙的211 万的新...
-

如何用python爬取网站数据?
这里简单介绍一下吧网页数据抓取,以抓取网站静态、动态2种数据为例,实验环境win10+python3.6+pycharm5.0,主要内容如下:抓取网站静态数据(数据在网页源码中):以糗事百科网站数据为例1.这里假设我们抓取的...
-

爬取其他网站的资讯,是否犯法?
爬虫本身在法律上并不被禁止,但是看你爬取数据的来源和途径了网页数据抓取。就好比卖刀的是合法的,到你用刀做违法的事,就被法律所不能容忍了。那么哪些是要承担有风险的尼?1.违法了爬取的网站的意愿,网站采取反爬取措施后,强行破解,...
-
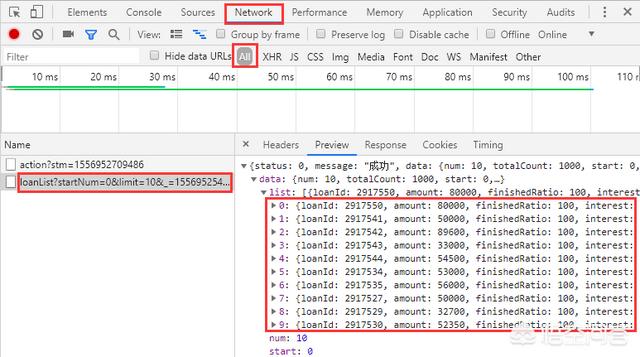
如何通过网络爬虫获取网站数据?
这里以python为例网页数据抓取,简单介绍一下如何通过python网络爬虫获取网站数据,主要分为静态网页数据的爬取和动态网页数据的爬取,实验环境win10+python3.6+pycharm5.0,主要内容如下:静态网页数...
-
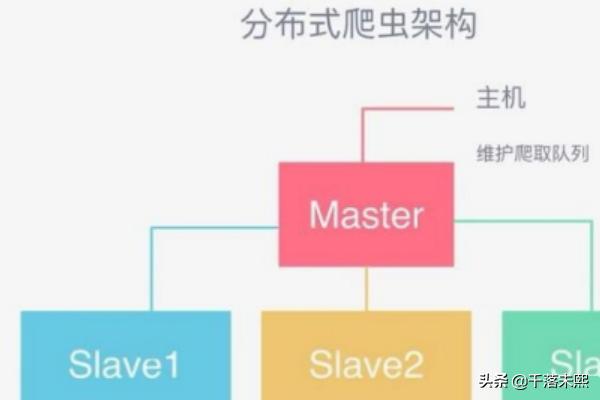
如何爬取网页数据?
1、URL管理首先url管理器添加了新的url到待爬取集合中网页数据抓取,判断了待添加的url是否在容器中、是否有待爬取的url,并且获取待爬取的url,将url从待爬取的url集合移动到已爬取的url集合页面下载网页数据抓...
-

Excel怎么抓取网络数据?
Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现网页数据抓取。例:下图是百度百科“奥运会”网页中的一个表格,我们以此为例实现抓取该表格至Excel中,并且能够通过输入第几届来查询对应的举办...
没有更多内容